Was ist der frustrierendste Part des automatisierten Web Scrapings? Dass du dich ständig mit IP-Kontrollen auseinander setzen musst. Genau bei diesem Problem kann ScraperAPI helfen.
Als Web Scraping bezeichnet man das Extrahieren, Kopieren und Speichern der Daten anderer Websites, um diese zu analysieren und möglicherweise auch anderweitig zu verwenden. Beim manuellen Scrapen werden die Inhalte einzeln und per Hand kopiert. Wenige Seiten stellen dabei natürlich kaum eine Herausforderung dar.
Web Scraping ist nach geltender Rechtssprechung legal, wenn die extrahierten Daten frei zugänglich für Dritte im Web stehen und natürlich das Urheberrecht berücksichtigt wird. Hierzu gibt es insbesondere ein höchstrichterliches Urteil, wo 2014 der Bundesgerichtshof (BGH) eine Klage des Billigfliegers Ryanair gegen ein Flugpreisvergleichs-Portal abwies.
Das Preisvergleichsportal griff per Web Scraping auf die Webseite der Fluglinie zu (I ZR 224/12). Das Urteil zur Legalität von Web Scraping stärkte somit auch die Verbraucher: Das Geschäftsmodell des Internet-Portals „fördere Preistransparenz auf dem Markt der Flugreisen und erleichtere es dem Kunden, die günstigste Flugverbindung aufzufinden“, begründete das Gericht sein Urteil.
Es ist aber natürlich wichtig, dass wenn Daten urheberrechtlich geschützt sind, dass du sie dann nicht woanders veröffentlichst.
Wenn du jedoch Hunderte, Tausende oder sogar Millionen von Seiten scrapen möchtest, dann kommen viele Herausforderungen auf dich zu, die dich am Zugriff auf die benötigten Daten hindern. Dafür gibt es Tools, die das automatisierte Scrapen möglich machen.
Durch diese Tools bekommst du die Möglichkeit, auch mit geringen oder keinen Programmierkenntnissen einen Web Scraper zu erstellen. Entwickler nutzen die Tools beispielsweise auch als Basis, um eigene Scraping-Lösungen zu entwickeln.
Welche Herausforderungen entstehen?
Mögliche Herausforderungen können Anti-Scraping-Techniken sein, die von Websites eingesetzt werden. Dazu gehören unter anderem IP-Tracking und Browser-Fingerprinting.
Besonders für Neulinge kann der Umgang mit all diesen Maßnahmen sehr mühsam sein. Aus diesem Grund wurden Web-Scraping-APIs eingeführt.
Was sind Web-Scraping-APIs?
Web-Scraping-APIs sind Dienstleister, die Web-Scrapern helfen, nicht gesperrt zu werden, indem sie den Umgang mit Anti-Scraping-Techniken bieten, die von Websites eingerichtet wurden. Sie verwenden Techniken wie IP-Rotation und andere interne Techniken, um sicherzustellen, dass die von dir angeforderte Seite für dich heruntergeladen wird. Sie vereinfachen also den gesamten Prozess des Web Scraping.
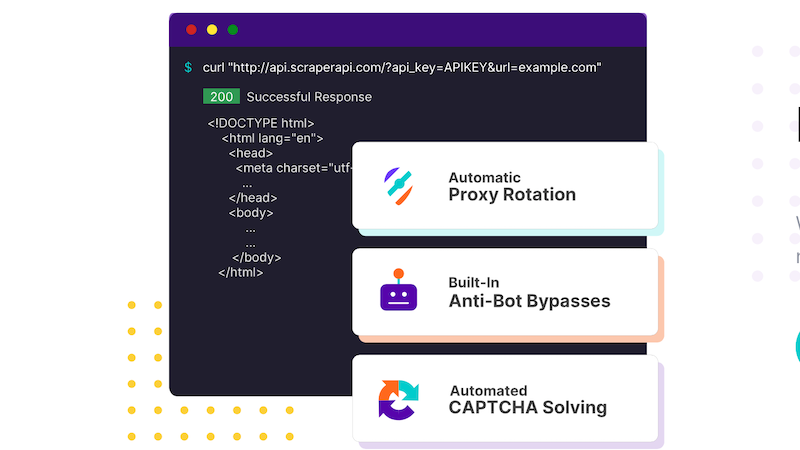
ScraperAPI: Web Scraping automatisieren
ScraperAPI rotiert die IP-Adressen bei jeder Anfrage aus einem Pool von Millionen von Proxys und wiederholt fehlgeschlagene Anfragen automatisch, sodass das Scraping reibungslos funktioniert.
Das Programm ist nicht nur einfach zu starten, sondern auch einfach anzupassen. Mit ScraperAPI kannst du Anfrage-Header, Anfragetyp, IP-Geolokalisierung und noch viel mehr anpassen. Erstelle Sessions, um IP-Adressen mehrfach wiederzuverwenden.
Unvergleichbare Geschwindigkeit und Zuverlässigkeit
Der Dienst entfernt langsame Proxys automatisch und regelmäßig aus ihren Pools und verspricht unbegrenzte Bandbreite mit Geschwindigkeiten von bis zu 100Mb/s, perfekt für das Schreiben von schnellen Webcrawlern. Mit einer Proxy-Infrastruktur, die 20 verschiedene ISPs umfasst, bietet sie unvergleichliche Geschwindigkeit und Zuverlässigkeit, so dass du problemlos skalierbare Webcrawler erstellen kannst.
Jetzt selbst von ScraperAPI überzeugen
Nutze jetzt auch du den Dienst von ScraperAPI, um dich nicht ständig über IP-Kontrollen ärgern zu müssen. Hier kommst du direkt zu ScraperAPI.